|
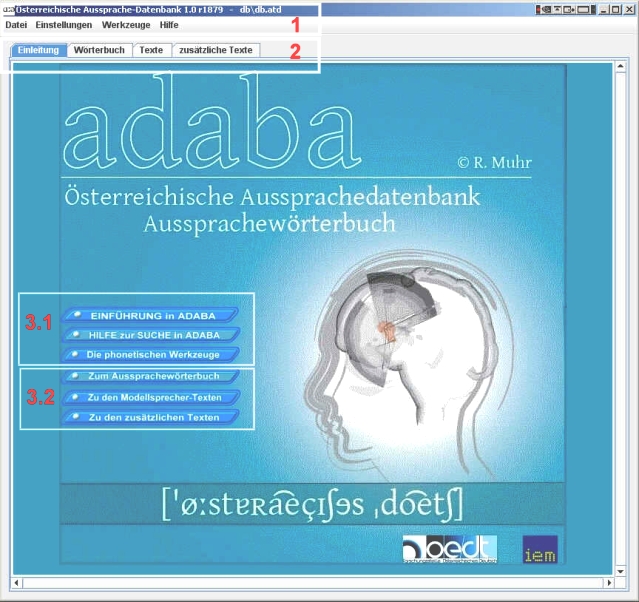
1. Die ADABA-Datenbankoberfläche Wenn Sie die ADABA-DB das erste Mal starten, wird die folgende Oberfläche anzeigt.
Es stehen drei Menüleisten zur Verfügung:
|
|
2. Überblick über die Suchmöglichkeiten in der ADABA-Datenbank:
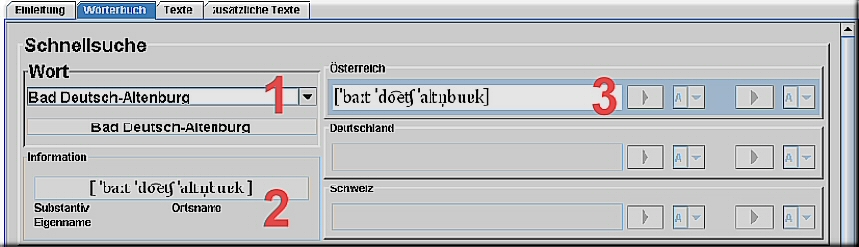
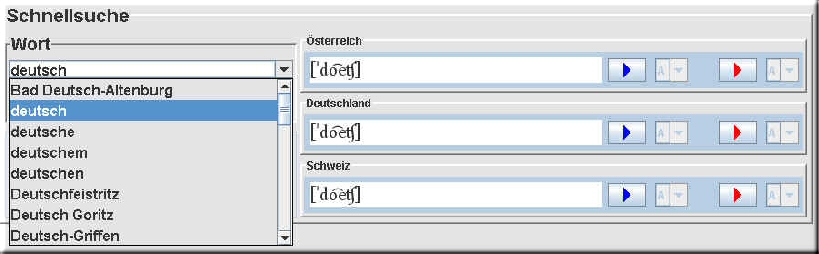
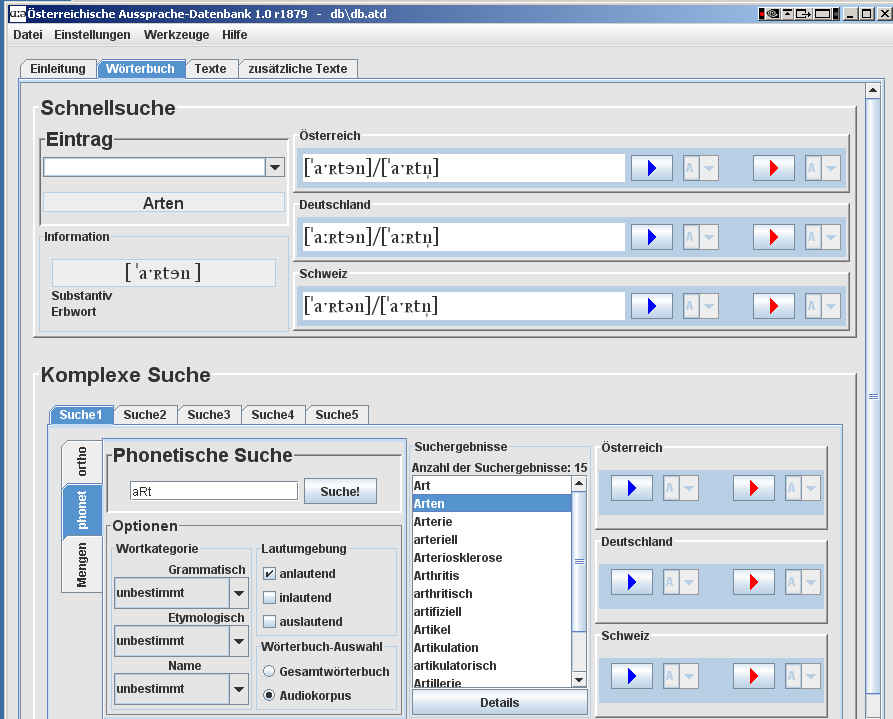
2.1 Schnellsuche und Abhören von Wörtern: Anzeigefelder <1>, <2> und <3> Durch Anklicken der einzelnen Kartenreiter kommen Sie zu den einzelnen Abschnitten der ADABA-Datenbank. Wählen Sie nun den Kartenreiter "Wörterbuch". Sie kommen damit zur Wort-Datenbank. Dort finden links oben die Schnellsuche.
Die Schnellsuche wird HIER im Detail erklärt. 2.2 Die komplexe Suche - Überblick Die ADABA-Aussprachedatenbank bietet neun verschiedene Suchmöglichkeiten an, mit deren Hilfe komplexe Suchen durchgeführt werden können. Alle Suchoptionen können miteinander kombiniert werden.
Folgende Suchmöglichkeiten stehen zur Verfügung:
|
|
3. Die Suchmöglichkeiten in der ADABA-DB im Detail
3.1. Schnellsuche und Abhören von Wörtern im Detail: Durch Anklicken der einzelnen Kartenreiter kommen Sie zu den einzelnen Abschnitten der ADABA-Datenbank. Wählen Sie nun den Kartenreiter "Wörterbuch". Sie kommen damit zur Wort-Datenbank. Dort finden eine Reihe von Feldern. 1. Die Schnellsuche: Anzeigefelder <1>, <2> und <3>
|
|
2. Die Abspielfunktion für die Audiodateien
|
|
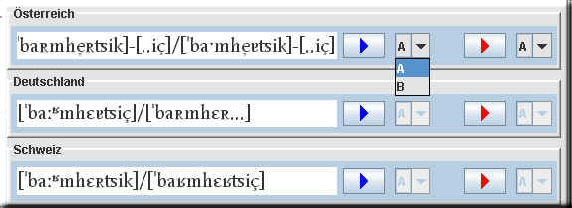
3. Die Transkription: Anzeigefelder <3> und <4>
Bei der Darstellung der Transkription gelten folgende Konventionen:
|
|
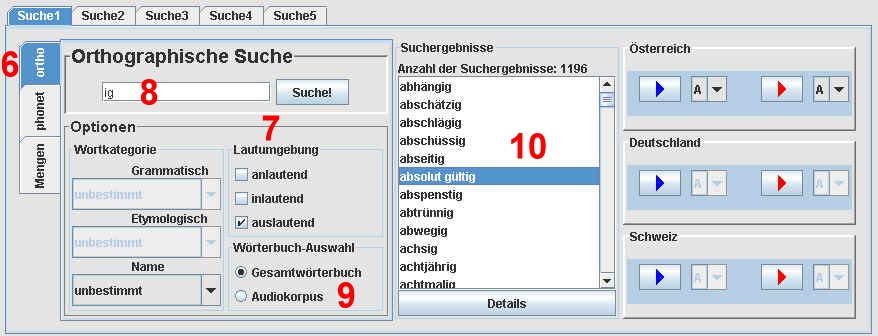
3.2. Die orthographische Suche Basis dafür ist die Orthographie des jeweiligen Wortes oder eine beliebige Zeichenfolge, die aus den 30 Buchstaben des Deutschen besteht.
Für die Umgebungssuche kann im Feld (7) eine oder mehrere der drei Optionen "anlautend", "inlautend" oder "auslautend" aktiviert werden.
Gehen Sie dazu folgendermaßen vor:
|
|
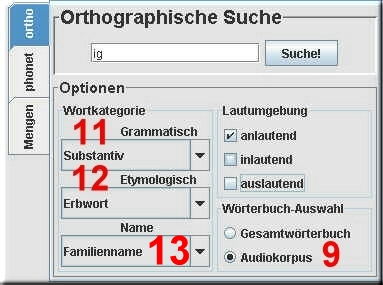
3.3 Die Wortkategoriensuchen I und II I. Die Suche mit Hilfe von grammatischen und etymologischen Merkmalen (Feld 11 und 12) II. Die Suche nach Namen (Feld 13) Alle Such-Abfragen in der ADABA-Datenbank können mit Hilfe von grammatischen und etymologischen Kritierien präzisiert (eingeschränkt) werden. Diese Option steht nur für den Audiokorpus zur Verfügung! Die Wörter des Nicht-Audiokorpus sind NICHT grammatisch und etymologisch annotiert.
Gehen Sie dazu folgendermaßen vor:
Die Optionen sind:
2. Ein komplexes Suchbeispiel:
|
|
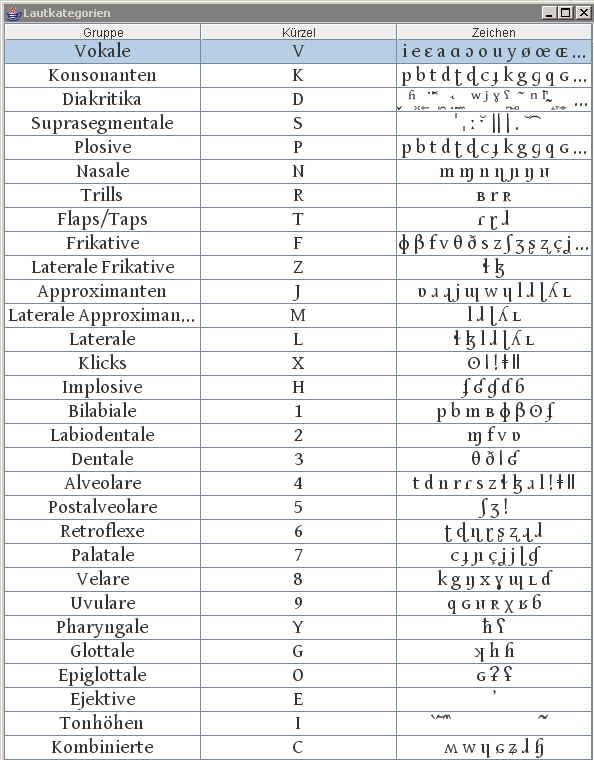
4. Die phonetische Suche mit Hilfe der phonetischen Werkzeuge der ADABA-DB - Überblick In der ADABA-Datenbank kann auch mit Hilfe von IPA-Lautsymbolen oder anhand von Lautkategorien (Konsonant, Plosiv, Vokal usw.) suchen und sich alle Wörter ausgeben lassen, die genau die gesuchten phonetischen Merkmale haben. Dazu ist die Verwendung des Zeichensatzes der IPA notwendig. Die IPA-Zeichen werden Hilfe eines SAMAP-IPA Konverters erzeugt, der im Haupmenü unter Werkzeuge aufgerufen werden kann und anschließend erklärt wird. Gleichzeitig ist die Verwendung der X-SAMPA-Austria Tabelle notwendig, da die Eingabe der IPA-Zeichen über Standardtastaturen nicht möglich ist.
5.
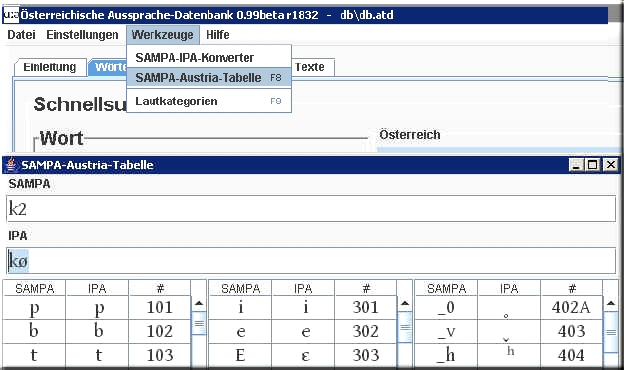
Die phonetischen WERKZEUGE der ADABA-Datenbank - Die Eingabe phonetischer Zeichen 1. Begriffsklärung 1: Was ist unter SAMPA zu verstehen? SAMPA ist die Abkürzung für Speech Assessment Methods Phonetic Alphabet ist die Kurzbezeichnung für ein phonetisches Alphabet, das mit den 127 Zeichen des ASCII-Zeichensatzes auskommt. Es kann damit über jede handelsübliche Tastatur eingegeben werden, braucht aber entsprechende Zeichensätze bzw. Konverter, damit die SAMPA-Zeichen in IPA-Zeichen umgewandelt werden. 2. Begriffsklärung 2: Was ist unter X-SAMPA Austria zu verstehen? X-SAMPA Austria ist die österreichische Version von SAMPA, die im Rahmen des ADABA-Projekts erstellt wurde. Dies war notwendig, da sich die deutsche Version von SAMPA als zu wenig differenziert erwiesen hatte. Die ursprünglichen SAMPA-Konventionen wurden wo immer möglich eingehalten und lediglich in einigen Punkten eine Ergänzung vorgenommen. Basis der Kodierung ist weiters der True Type Font MS Arial Unicode bzw. SIL Gentium Alt. Beide wurden für die Transkription bzw- für die Darstellung in der ADABA-Datenbank verwendet. Ein Überblick findet sich im Kapitel X-SAMPA-Austria.
3. Die X-SAMPA Austria Tabelle und der SAMPA-IPA Konverter: a. Aufrufen der SAMPA-Austria Tabelle: Über den Hauptmenü-Punkt "Werkzeuge". Es öffnet sich ein Fenster, mit einer Tabelle, in der spaltenweise SAMPA- und IPA-Zeichen gegenübergestellt sind.
b. Verwenden des SAMPA-IPA Konverters:
c. Die Kurzversion des SAMPA-IPA-Konverters: Unter dem Menüpunkt "Werkzeuge-IPA-SAMPA-Konverter" kann eine Kurzversion des SAMPA-IPA Konverters aufgerufen werden. Er ist für Phonetiker und erfahrene SAMPA-Transkribierer gedacht, die die SAMPA-Zeichen bereits kennen. Die Kurversion besteht nur aus den beiden Eingabefeldern SAMPA <-> IPA. Die Funktionalitiät ist identisch mit dem Konverter, der in die SAMPA-Tabelle eingebunden ist und unter Punkt a. beschrieben wurde.
|
|
6. Die Suche mit Hilfe phonetischer Lautsymbole: Die Suche mit Hilfe phonetischer Lautsymbole in der ADABA-Datenbank ermöglicht es, dass auch innerhalb von Transkriptionen gesucht werden kann. Dazu ist die Verwendung des Zeichensatzes der IPA notwendig. Gehen Sie folgendermaßen vor: (1). Die IPA-Zeichen können Sie mit Hilfe des SAMPA-IPA Konverters und der SAMPA-Austria Tabelle eingeben. Verwenden Sie dazu den unter Pkt. V.1 beschriebenen SAMPA-IPA Konverter. (2) Klicken Sie auf den Kartenreiter mit der Aufschrift "phonet". (3) Kopieren Sie die IPA-Zeichen in das Suchfeld und aktivieren Sie eine oder mehrere Optionen der Umgebungssuche. Die phonetische Suche kann wie die orthographische Suche mit zusätzlichen Kriterien spezifiziert werden. (4) Klicken Sie auf "Suche". Das Ergebnis wird im FEld "Suchergebnisse" ausgegeben. (5) Im nachfolgenden Beispiel wurde nach der phoentischen Sequenz [aRt] (anlautend) gesucht. Das Ergebnis sind 15 Wörter, in denen diese Sequenz anlautend vorkommt.
|
|
7. Die Suche mit Hilfe phonetischer Lautkategorien:
Statt phonetischer Lautsymbole können Sie
mit Hilfe von Symbolen für ganze
Lautkategorien suchen. Es werden dann Wörter gesucht, in denen
die Laute vorkommen, die zur jeweiligen IPA-Kategorie
gehören.
|
|
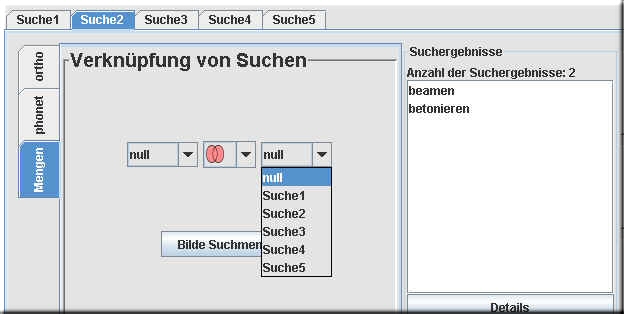
Mit der Mengensuche können Sie aus mehreren einzelnen Suchabfragen neue Mengen bilden. Es sind dies die Vereinigungsmenge, die Differenzmenge oder die Menge gemeinsamer Elemente.
Durchführung:
Ein Suchbeispiel:
|
|
Die Suche nach Namen ist sowohl im Audiokorpus, als auch im Gesamtwörterbuch möglich. Allerdings in dieser Version (noch nicht) in beiden gleichzeitig. Die Namen im Audiokorpus sind nur als "Eigenname" markiert, die Namen im "Gesamtwörterbuch" nach "Familiennamen" und "Ortsnamen" differenziert.
9.1 Die Suche nach Familiennamen oder Gemeindenamen im Gesamtwörterbuch: Im Gesamtwörterbuch sind 2.101 häufige österreichischen Familiennamen und die Aussprache aller 2.353 österreichischen Gemeindenamen enthalten. Für die Suche nach diesen Namen gehen Sie folgendermaßen vor:
9.2 Die Suche nach Eigenamen im Audiokorpus: Im Audiokorpus sind rund 450 Eigennamen enthalten. Für die Suche nach diesen Namen gehen Sie folgendermaßen vor:
|
| 10.
Exportieren der Suchergebnisse:
Die Suchergebnisse können Sie exportieren, indem Sie im Menüpunkt "Datei / Suchergebnisse exportieren..." eine der beiden Optionen wählen:
|
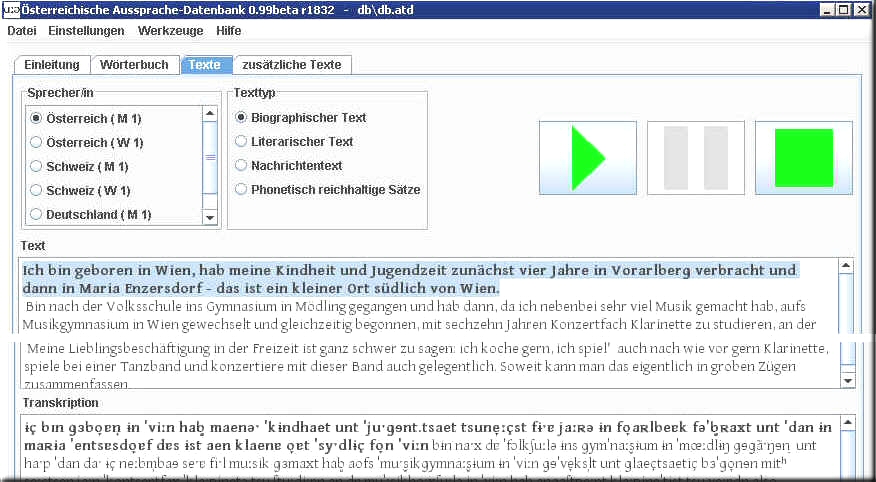
| 11. Das Abhören der Texte:
Die in der Datenbank enthalten Texte können Sie abhören, indem Sie auf die Felder "Texte" bzw. "Zusätzliche Texte" klicken. Sie finden dort ein Menü, in dem Sie die jeweiligen SprecherInnen und den jeweiligen Text auswählen können. Die ModellspecherInnentexte I (Menü "Texte") liegen transkribiert vor, die ModellspecherInnentexte II (Menü "Zusätzliche Texte") liegen nur in orthographischer Umschrift vor. Wichtig: Das Abspielen beginnt jeweils 30 Millisekunden vor einer markierten Stelle und überlappt anschließend bis zu einer segmentierten Einheit, die jedoch im Text nicht sichtbar ist. Zum Abhören stehen zwei Möglichkeiten zur Verfügung:
11.1. Abspielen der gesamten Textes:
11.2 Abspielen von markierten Teilen:
|
|
|